
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 2021 Dev-matching 웹 백엔드 개발자
- 웹 프로그래밍
- cs50
- 풀스택
- 서버
- 장고
- 웹
- Naver boostcourse
- 서블릿
- QNA 봇
- Django
- 4기
- boostcourse
- AI Tech 4기
- BOJ
- 레벨2
- 파이썬
- 프로그래밍
- Naver boostcamp
- 백준
- 구현
- 프로그래머스
- AI Tech
- 대회
- Customer service 구현
- 네이버
- P Stage
- 부스트캠프
- 백엔드
- sts
- Today
- Total
daniel7481의 개발일지
[웹 프로그래밍(풀스택)] SQL - BE 본문
1. SQL이란? -1
SQL(Structured Query Language)은 데이터를 쉽게 추가, 삭제, 수정할 수 있도록 고안된 컴퓨터 언어이다.
관계형 데이터베이스에서 데이터를 조작하고 쿼리하는 표준 수단이다.
크게 세가지로 나눠져있다
- DML(Data Manipulation Language, 조작어): 데이터를 조작하기 위해서 사용한다
- INSERT, UPDATE, DELETE, SELECT등이 여기에 해당한다
- DDL(Data Definition Language, 정의어): 데이터베이스의 스키마를 정의/조작하기 위해 사용한다
- CREATE, DROP, ALTER등이 해당된다
- DCL(Data Control Language, 제어어): 데이터를 제어하는 언어. 권한을 관리하고, 데이터의 보안, 무결성 등을 정의한다.
- GRANT, REVOKE 등이 해당된다
DB 생성하기
먼저 DB를 관리하기 위해서는 DB를 생성해야 할 것이다. 명령 프롬프트에서 mysql -uroot -p를 입력하면 비밀번호를 입력하라고 뜰 것이다. 거기에다 본인이 설정했던 비밀번호를 입력하면 된다. 여기서 우리는 root로 접속을 한 것이다. 이제 DB를 생성할 것인데 mysql> create dabase DB이름으로 하면 된다. 이렇게 DB를 생성할 수 있는 유저의 권한은 따로 있는데 우리가 접속한 root는 다 가능하다. 생성했으면 Query OK라고 뜨는 것을 알 수 있다. 여기서 Query란 질의로 해석할 수 있는데, 우리가 DB에 대한 명령문을 가르키는 것이다. 사용자가 질의(Query)를 DB 서버로 보내고, DB 서버가 결과를 사용자에게 보내는 점에서, 서버와 클라의 관계와 유사하다고 볼 수 있겠다. 이제 사용자와 권한을 정해줘야 한다.
8.0버전 이상부터는 예제와는 살짝 다르게 입력을 해야한다.
grant all privileges on connectdb.*to 'connectuser'@'%' identified by 'connect123!@#';
flush privileges;grant란 권한을 주는 DCL이다. all privileges는 모든 권한을 얘기하는 것이고, db이름.*, 이 뒤에 있는 *은 모두를 의미하는 것이다. 여기서는 DB의 모든 권한을 다 준다는 것이다. 이처럼 권한을 골라서 줄 수 있다. 계정이름@뒤에 나오는 '%' 또한 모든이라는 뜻이 있어서, 모든 클라이언트가 접근할 수 있다는 것이다. 뒤에 localhost라고 하면 현재 컴퓨터에서만 접근이 가능하다는 뜻이다. 맨 밑에 있는 flush privilages;를 써야만 DBMS에 적용이 된다. 우여곡절 끝에? connectuser로 connectdb에 접속할 수 있었다. mysql 사용중에 연결을 끊고 싶으면 exit 혹은 quit;을 치면 된다. 그러면 Bye하고 귀엽게 나올 수 있다.
이제 DML인 select을 살짝 맛만 볼건데, select문은 무언가를 DB에게서 요청하는 명령문이라고 생각하면 된다. 예로 select version(), current_date();을 치면 현재 버전과 날짜가 나온다.
특징
- 실습을 통해 알 수 있지만 SQL에서 쿼리는 ;(세미콜론)으로 끝나야 한다.
- 결과가 나온 것을 보면 전체의 몇줄이고, 검색하는데 드는 시간을 보여준다.
- 키워드 같은 경우에는 대소문자를 구분하지 않는다. 또한 쿼리를 이용해서 계산식의 결과를 구할 수도 있다.
- 여러 문장을 한 줄에 세미클론을 사이에 두고 연속으로 붙여서 사용도 가능하다.
- ;을 입력하지 않은 이상 쿼리가 끝나지 않기 때문에 엔터를 치면서 여러 줄로 쓸 수 있다.
- 중간에 입력하다 취소하고 싶으면 \c를 치면 된다.
- 우리가 현재 DBMS에 어떤 DB가 존재하는지 알고 싶으면 show databases를 치면 된다.
- user 데이터베이스명을 이용하여 데이터베이스를 전환할 수 있다. 당연히 데이터베이스가 존재해야하며 현재 접속중인 계정이 그 DB에 대한 권한이 있어야 한다.
2. SQL이란? -2
DB안에는 데이터가 있어야하므로 데이터를 넣어보자. 우리가 사용하는 MySQL은 관계형 DB(RDBMS)이다.

RDBMS는 테이블로 데이터가 저장이 되는데, 테이블은 한 개 이상의 column과 0개 이상의 row로 구성이 되어 있다. column은 세로로 한 가지 종류(데이터 타입/크기)를 가지고 있다. row 같은 가로(aka 레코드)는 칼럼들의 값의 조합이다. 이러한 레코드는 기본 키에 의해서 구분되고, 기본 키는 중복될 수 없다. 필드는 row와 column의 교차점으로 데이터를 포함할 수 있고, null값을 가질 수 있다.
일단 우리 DB에 테이블이 있는지 확인해보자. 만든 적이 없는데 있으면 이상할 것이다. show tables;로 확인을 해보면 Empty set;이라고 나온다. 이제 강좌에서 주어진 examples.sql을 다운한 후, 터미널에서 examples.sql이 있는 폴더로 이동한 후에 mysql -uconnectuser -p connectdb < examples.sql을 입력하자. 이제 connectuser로 connectdb에 접속해보자. 아까처럼 show tables로 examples.sql에 있던 테이블이 잘 들어갔는지 확인해보자. 이번에는 7개의 테이블이 들어가 있는 것을 알 수 있다. 이제 더 자세히 bonus라는 테이블에 대해 알고 싶다고 하면 desc(describe) bonus;를 하면 된다. 안에는 무슨무슨 칼럼이 있고, 타입과 조건, 기본키 여부 등이 나와있다.
3. DML(select, insert, update, delete)-1
데이터 조작어는 select(검색), insert(등록), update(수정), delete(삭제)가 있다.
Select 구문의 기본 문형

DISTINCT는 중복행을 제거할지 여부이고 괄호로 되어있는 것은 필수는 아니라는 뜻이다. SELECT는 ~를 보여주세요라는 의미로 생각하면 되는데, ALIAS는 칼럼들을 보여줄 때 별칭으로 부를 것인지 나타내는 것이다. 위를 해석해보면 ~테이블에서 ~칼럼에 대한 내용을 보여주세요라고 생각하면 되겠다. *(별표)같은 경우에는 모두라는 뜻이 있고, SELECT 뒤에 *을 쓰면 모든 데이터를 출력해주세요라고 할 수도 있다.
ALIAS만 별도로 설명을 하자면, 여러 가지 칼럼들은 쉼표를 사이에 두고 쓰는데, 어떤 칼럼에 대한 별칭은 다음 칼럼으로 넘어가는 쉼표 이전에 작성해야 한다.
select empno as 사번, name as 이름, job as 직업 from employee;여기서 as는 사용해도 되고 안해도 된다.
칼럼의 합성(Concatenation)
문자열 결합함수 concat 사용
SELECT concat( empno, '-', deptno) AS '사번-부서번호'
FROM employee;이러면 칼럼명은 사번-부서번호로 나오고, 밑에 레코드들은 두 가지 문자열을 합친 값이나오게 된다.
다음은 앞에서 설명한 바 있는 DISTINCT이다. DISTINCT는 중복되는 부분을 삭제하고 레코드들이 나오게 된다.
SELECT DISTINCT deptno from employee를 하게 되면 10과 20과 30이 무수히 많았던 원래와 달리 중복된 값들이 사라져서 10, 20, 30만 나오게 된다.
정렬
레코드들을 순서대로, 혹은 역순대로 출력하고 싶으면 order by, descending을 사용하면 된다.

select empno, name, job from employee order by name;이러면 이름을 기준으로(a부터) 순서대로 출력을 하게 되고,
select empno, name, job from employee order by name desc;밑은 역순대로 출력하게 된다.
4. DML(select, insert, update, delete)-2
Select구문 중 특정 행을 검색할 수 있는 where절을 알아보자

예제에서처럼 select * from employee where job = 'salesman';으로 하면 직업이 salesman인 사람들의 정보가 출력이 될 것이다. 이처럼 다양한 예제들을 실행시켜보았다.
또한 in 구절을 사용해볼 수 있다.
select * from employee where deptno in (10, 30);위와 같이 치면 employee 테이블에서 deptno가 10 혹은 30인 사람들의 모든 정보가 나온다. 여기서 괄호 안에 들어가는 것은 조건들이다. 혹은 =을 이용할 수도 있고, <, >, <=, >= 또한 당연히 사용 가능하다. 비교 연산자인 OR, AND, NOT 연산도 사용할 수 있다.
select * from employee where deptno = 10 or deptno = 30;
select * from employee where deptno = 10 and salary < 1000;
select * from employee where not deptno = 10;LIKE 키워드
- 와일드 카드(%: 0에서부터 여러 개의 문자열을 나타냄, _: 단 하나의 문자를 나타내는 와일드 카드)를 사용하여 특정 문자를 포함한 값에 대한 조건을 처리
ex: employee 테이블에서 이름에 A가 포함된 사원의 이름과 직업을 출력하시오.
select name, job from employee where name like '%A%';위에는 앞 뒤에 와일드카드를 붙힘으로써 앞 뒤에 어떠한 문자가 여러 개 있어도 상관없다는 뜻이다. 만약 한 문자만 앞에 있는 것을 원했다면 _를 사용해야 했을 것이다. 위에서는 ALLAN, JAMES 등 여러 사람들이 나온다. 그러나 _A%를 하게 되면 어떻게 될까? 앞 글자 하나만 용납하고 뒤에는 여러 글자가 있어도 상관 없기 때문에 WARD, MARTIN, JAMES가 출력이된다.
함수의 사용
UCASE, UPPER(모든 글자를 대문자로 바꾸는 함수), LCASE, LOWER(모든 글자를 소문자로 바꾸는 함수)와 같이 함수를 사용할 때의 문법이다.
mysql > select lower('SEoul'), upper('SEoul');Oracle 같은 경우에는 from 다음에 무조건 테이블이 나와야 하기 때문에 DUAL이라는 임시 테이블을 지정하여 선언해주기도 하는데, mySQL 같은 경우에는 테이블명을 선언하지 않더라도 이러한 함수 사용이 가능하다.
이제 select문에서 이름을 모두 소문자로 출력을 하고 싶을 때는 다음과 같이 하면 된다.
select lower(name) from employee;다음으로는 substring 함수를 알아보자
select substring('Happy Day', 3, 2)위 결과로는 pp가 나오게 된다. 이름처럼 첫 번째 인자는 문자열이고, 두 번째 인자는 인덱스이다(mySQL에서는 인덱스가 1부터 시작한다). 세 번째는 인덱스로부터 어디까지 출력할 것인지를 정하는 인자이다. 여기서는 3번째부터 2개, 즉 3, 4번 인덱스인 pp가 출력이 됬다.
LPAD, RPAD
우리가 원하는 문자열의 길이가 되지 않을 경우 어떠한 문자열로 채워주라는 함수이다.
select LPAD("hi', 5, '?'), RPAD('joe', 7, '*');첫 번째 인자는 문자열이고, 두 번째는 우리가 원하는 문자열의 길이가 되겠다. 마지막 인자는 공백 대신 채워줄 문자인데, LPAD는 문자열을 기준으로 왼쪽을 채우고, RPAD는 문자열을 기준으로 오른쪽을 채우게 된다. 위 결과로는 ???hi, ****joe가 출력이 된다.
TRIM, LTRIM, RTRIM
LTRIM, RTRIM은 왼쪽/오른쪽에 공백이 존재할 경우 공백을 제거하는 함수이다. 우리가 외부로부터 정보를 받아올 때 클라이언트로부터 값을 받아올 때 클라이언트가 잘못된 공백을 넣어줬다던지 이러한 공백 때문에 문제가 발생할 수도 있다. 그러므로 이러한 함수를 쓴다.
그 외 함수들
- FLOOR(x) : x보다 크지 않은 가장 큰 정수를 반환합니다. BIGINT로 자동 변환합니다.
- CEILING(x) : x보다 작지 않은 가장 작은 정수를 반환합니다.
- ROUND(x) : x에 가장 근접한 정수를 반환합니다.
- POW(x,y) POWER(x,y) : x의 y 제곱 승을 반환합니다.
- GREATEST(x,y,...) : 가장 큰 값을 반환합니다.
- LEAST(x,y,...) : 가장 작은 값을 반환합니다.
- CURDATE(),CURRENT_DATE : 오늘 날짜를 YYYY-MM-DD나 YYYYMMDD 형식으로 반환합니다.
- CURTIME(), CURRENT_TIME : 현재 시각을 HH:MM:SS나 HHMMSS 형식으로 반환합니다.
- NOW(), SYSDATE() , CURRENT_TIMESTAMP : 오늘 현시각을 YYYY-MM-DD HH:MM:SS나 YYYYMMDDHHMMSS 형식으로 반환합니다.
- DATE_FORMAT(date,format) : 입력된 date를 format 형식으로 반환합니다.
- PERIOD_DIFF(p1,p2) : YYMM이나 YYYYMM으로 표기되는 p1과 p2의 차이 개월을 반환합니다.
- ABS(x): x의 절대값을 구합니다
- MOD(n, m) 아니면 %: n을 m으로 나눈 나머지 값을 출력합니다
출처: Naver Boostcourse
5. DML(select, insert, update, delete)-3
이번 장에는 형변환을 할 수 있는 CAST 함수에 대해 알아보자

오라클에서는 TO_CHAR, TO_NUMBER 등의 함수들을 이용하여 형변환을 하게 되는데, mySQL에서는 4.2버전부터 CAST, CONVERT 등의 함수로 형변환이 가능하다.
그룹함수
앞에서 살펴보았던 LPAD 같은 함수들은 하나의 칼럼만 다루는 단일 함수이다. 그룹 함수는 여러 개의 칼럼 값을 가지고 하나의 결과 값을 만들어내는 함수이다. 다음은 그룹 함수의 종류이다.

예로 들어 select concat(name, 'aaa') from employee라고 하자. name이라는 칼럼의 모든 값에 대해 aaaa를 붙힌 값이 출력이 된다. 이렇듯 칼럼의 모든 레코드들에 적용된 값이 출력이 되는 것을 단일 함수라고 한다. 그러나 select count(*) from employee;라고 하게 되면 14라는 하나의 결과값만 가지게 된다. 이러한 함수를 그룹 함수라고 한다. 위 함수들의 결과를 보면 평균, 분산, 표준 편차 등 한 칼럼에 대한 한 가지 결과값을 출력하는 함수이다.
group by절
만약 부서별, 직업별 등의 정보를 그룹 별 정보를 얻고 싶으면 group by를 사용하면 된다. 아래와 같은 문법을 가진다.
select deptno, av(salary), sum(salary) from employe
-> groupby deptno;deptno(10, 20, 30)에 따라서 salary의 평균값과 salary의 합계가 출력이 되는 모습을 볼 수 있다.
만약 나는 이름과 salary의 평균 값을 알고 싶다고다음과 같이 적었다고 가정해보자.
select name, avg(salary) from employee;이러면 평균값과 함꼐 하나의 이름만 출력이 되는 것을 알 수 있다. 이는 당연히 틀린 결과일 것이다. 이렇듯 그룹별로 결과를 출력하고 싶다면 마지막에 group by문을 꼭 적어주는 것을 잊지 말자.
6. DML(select, insert, update, delete)-4
데이터 입력(INSERT문)
INSERT INTO 테이블명(필드1, 필드2, 필드3, 필드4,...)
VALUES(필드1 값, 필드2 값, 필드3 값, 필드4 값...)위와 같이 각 필드에 맞게 필드 값을 순서대로 매핑시켜서 넣어줘야 한다. 여기서 필드명을 지정해주는 방식은 디폴트 값이 세팅되는필드는 생략할 수 있다.
필드명을 지정해주는 방식은 추 후, 필드가 추가/변경/수정 되는 변경에 유연하게 대처가 가능하다. 또한 필드명이 생략되어 테이블명만 적을 시에는 반드시 모든 필드 값이 입력이 되어야 한다. 여기서 필드 순서는 테이블을 생성할 때 그 구문에서 만들어진 순서이며, desc 했을 때 나오는 순서이다. 위와 같은 경우는 원하는 필드만 넣어주겠다 할 때만 넣어주는 것이다. 이제 connectdb에서 role 테이블에 role_id가 200이고 description이 'CEO'인 레코드를 입력해보자.
mysql> insert into role values(200, 'CEO');여기서는 모든 필드에 대한 값을 넣어줄 것이기 때문에 따로 필드명은 쓰지 않았다.
이제 만약 description만 입력해주었다고 해보자. ERROR 1364 (HY000): Field 'role_id' doesn't have a default value가 뜨는 것을 알 수 있다. 이처럼 만약 칼럼이 NOT NULL조건이 있거나 기본키인 경우에는 입력을 필수로 해줘야 한다. 반대로 description을 입력하지 않고 role_id만 넣어줬을 때에는 정상적으로 처리가 되는 것을 알 수 있다.
데이터 입력(UPDATE문)
칼럼의 내용을 수정할 수 있는 구문이다.
UPDATE 테이블명
SET 필드1=필드1의 값, 필드2=필드2의 값...
WHERE 조건식조건식을 통해 조건에 맞는 row만 수정할 수 있다. SET에서 어떤 칼럼의 값을 무슨 값으로 바꿔줄 것이다를 설정할 수 있다. WHERE절이 필수는 아니지만 생략할 경우 모든 데이터가 바뀔수도 있다.
예제로 아까 만들었던 role_id=200, description='CEO'인 레코드를 description='CTO'로 바꿔보자
mysql> update role
-> set description='CTO'
-> where role_id=200;데이터 삭제(DELETE문)
DELETE
FROM 테이블명
WHERE 조건식매우 간단하지만 여기서도 WHERE 뒤에 조건식이 온다. WHERE문이 존재하지 않아도 되지만 여기서도 주지 않으면 전체 테이블이 삭제될수도 있으니 조심하자. 자 마지막으로 아까 만들었던 role_id가 200인 정보를 삭제해보자
mysql> delete from role where role_id = 200;7. DDL(create, drop)
DDL(데이터 정의어)는 DB의 스키마 객체를 생성/변경/제거하는데, 일단은 테이블만 다룰거지만, 실제로는 뷰라던지 synonym, index 등 다양한 개게를 생성/변경/제거할 수 있다.
일단 테이블을 정의하기 위해서 어떤 어떤 필드를 정의할거고, 해당 필드들은 어떤 데이터타입이고, 얼만큼의 자릿수를 차지할 것인지 등을 정의해야 한다. 이 때 필요한 것이 데이터 타입이다.
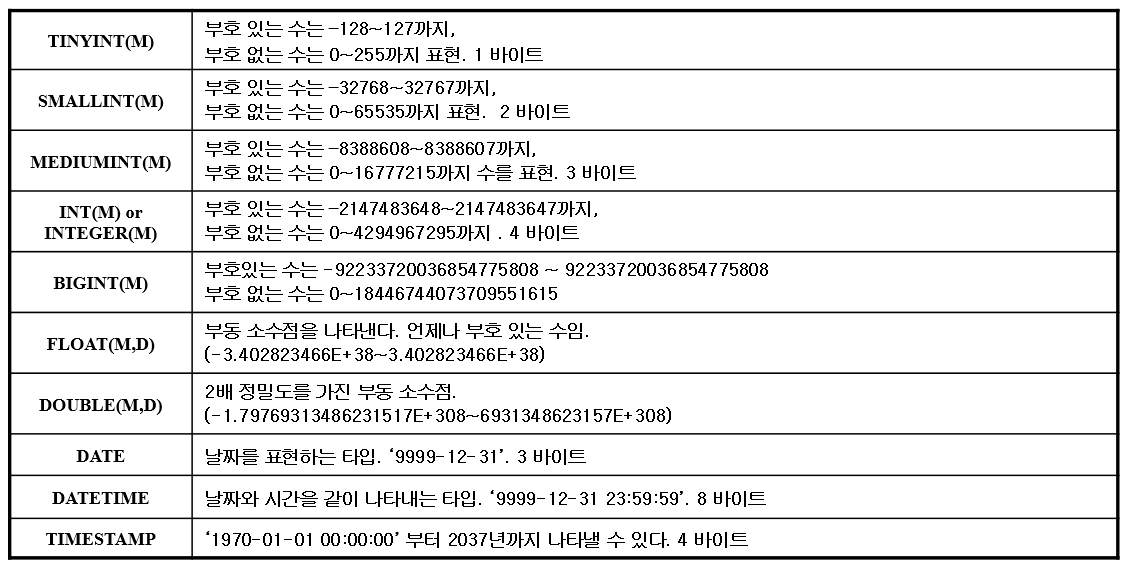

테이블을 생성할 때 필요한 구문부터 살펴보자
create table 테이블명(
필드명1 타입 [NULL | NOT NULL][DEFAULT ][AUTO_INCREMENT],
필드명2 타입 [NULL | NOT NULL][DEFAULT ][AUTO_INCREMENT],
필드명3 타입 [NULL | NOT NULL][DEFAULT ][AUTO_INCREMENT],
...........
PRIMARY KEY(필드명)
);create는 테이블 뿐만 아니라 user, database와 같다. 테이블은 각각의 필드가 필요하므로 각 필드의 이름과 데이터 타입, 제약조건 등을 줄 수 있다. NOT NULL은 NULL이 될 수 없다던지, 아니면 DEFAULT 값을 준다던지, 아니면 자동으로 값이 늘어나는 옵션 등을 줄 수 있다. 맨 밑에는 기본키(PRIMARY KEY)로 지정할 필드명을 줄 수 있다.

다음과 같은 필드를 가진 테이블 employee2를만들어보자
CREATE TABLE EMPLOYEE2(
empno INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(10),
job VARCHAR(9),
boss INTEGER,
hiredate VARCHAR(12),
salary DECIMAL(7, 2),
comm DECIMAL(7, 2),
deptno INTEGER);NULL이 default로 있기 때문에 따로 적어줄 필요는 없다. PRIMARY KEY를 바로 줄 수 있고 마지막에 선언할 수도 있다.
테이블 수정(컬럼 추가/삭제)
alter table 테이블명
add 필드명 타입 [NULL | NOT NULL][DEFAULT ][AUTO_INCREMENT];
alter table 테이블명
drop 필드명;칼럼을 추가하려면 add, 삭제하려면 drop을 사용하면 된다.
테이블 수정(컬럼 수정)
alter table 테이블명
change 필드명 새필드명 타입 [NULL | NOT NULL][DEFAULT ][AUTO_INCREMENT];컬럼의 데이터 타입이나 이름, 속성들을 바꾸고 싶으면 사용하는 것이다.
테이블 이름 변경
alter table 테이블명 rename 변경 이름테이블 삭제하기
drop table 테이블명;단 제약 조건이 있는 경우에는 drop 명령문으로 삭제할 수 없다. 예로 들어 한 테이블이 다른 테이블의 기본키를 참조하는 외래키를 가지고 있을 때, drop으로는 삭제할 수 없다. 실습으로 확인을 해보면 department 테이블의 기본키인 deptno가 있고, employee 테이블에서는 deptno를 참조하는 외래키가 존재한다. 이 상태에서 만약 department 테이블의 deptno 칼럼에서 존재하지 않는 값을 가지는 레코드를 employee 테이블에서 생성하려고 하면 에러가 발생하게 된다. 만약 employee 테이블이 department 테이블의 deptno 칼럼을 참조하고 있는데, 갑자기 department 테이블을 삭제한다고 해보자, 그러면 employee 테이블에 에러가 발생할 수 있기 때문에 그냥 지워지진 않는다. 이러한 경우에는 테이블을 생성한 반대로 삭제를 해야한다. 먼저 employee 테이블을 삭제한 후에 department 테이블을 삭제해야 한다는 것이다.
생각해보기
1. 칼럼의 길이가 10인데, 해당 칼럼에 값이 저장되어 있습니다. 이 때 칼럼의 길이를 5로 바꾼다면 어떤 일이 벌어질까요?
- 데이터가 없으면 영향을 받지 않지만, 만약 원래 길이보다 더 작게 줄일 경우 에러가 발생한다.
2. 문자열을 저장하는 데이터 타입인 CHAR와 VARCHAR 차이점에 대해 알아보고 어떤 상황에서 CHAR 또는 VARCHAR 를 선택하는 것이 효율적인지 생각해봅시다.
- 차이점은 저장 영역과문자열 비교 방법이다. VARCHAR 유형은 가변길이이므로 필요한 영역은 실제 데이터 크기이다. 그러므로 CHAR 유형보다 작은 영역에 저장할 수 있다. 또한 비교를 할 때 CHAR은 공백을 채워서 비교한다. 그러므로 'AA'=='AA '인 결과가 나오지만 VARCHAR은 공백또한 문자로 치기 때문에 'AA' != 'AA '란 결과가 나온다. 따라서 이름, 주소 등 길이가 변할 수 있는 값은 VARCHAR로 해주고 사번, 주민등록번호 같이 길이가 일정한 데이터는 CHAR을 사용하는 것이 유리하다.
'Naver Boostcourse' 카테고리의 다른 글
| [웹 프로그래밍(풀스택)] WEB API - BE (0) | 2022.02.23 |
|---|---|
| [웹 프로그래밍(풀스택)] JDBC - BE (0) | 2022.02.22 |
| [웹 프로그래밍(풀스택)] MySQL - BE (0) | 2022.02.14 |
| [웹 프로그래밍(풀스택)] JSTL & EL - BE (0) | 2022.02.14 |
| [웹 프로그래밍(풀스택)] Scope - BE (0) | 2022.02.13 |


