
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 백엔드
- 4기
- P Stage
- 풀스택
- Django
- 웹 프로그래밍
- 파이썬
- cs50
- 2021 Dev-matching 웹 백엔드 개발자
- 프로그래머스
- 서버
- 레벨2
- sts
- Naver boostcamp
- 백준
- 구현
- 부스트캠프
- AI Tech 4기
- 네이버
- 웹
- 서블릿
- BOJ
- Customer service 구현
- boostcourse
- Naver boostcourse
- AI Tech
- 장고
- QNA 봇
- 대회
- 프로그래밍
- Today
- Total
daniel7481의 개발일지
Wandb와 Sweep 구현 본문
P stage가 끝난 기념 폭풍같이 블로그를 작성하고 있다. 이 때가 아니면 또 잊어버릴 수도 있기에, 이번에 구현했던 wand와 sweep 구현을 적어보려고 한다.
Wandb
wandb.login(key = wandb_dict[cfg.wandb.wandb_username])
model_name_ch = re.sub('/','_',cfg.model.model_name)
wandb_logger = WandbLogger(
log_model="all",
name=f'{model_name_ch}_{cfg.train.batch_size}_{cfg.train.learning_rate}_{time_now}',
project=cfg.wandb.wandb_project,
entity=cfg.wandb.wandb_entity
)
# Checkpoint
checkpoint_callback = ModelCheckpoint(monitor='val_pearson',
save_top_k=1,
save_last=True,
save_weights_only=False,
verbose=False,
mode='max')
# Earlystopping
earlystopping = EarlyStopping(monitor='val_pearson', patience=2, mode='max')가장 먼저 wandb에 자동으로 로그인을 해주어야 한다. 이를 wand.login에서 실행하는데, key에 자신의 wandb api key값을 넣어주면 된다. 다음에 Trainer에 넣어줄 logger인 WandbLogger가 필요한데, wandb runs에 나타낼 이름을 설정해줄 수 있고, wandb 어느 project에 저장될지를 project에 넣어주고, entity에 기록을 저장할 entity 이름을 쓰면된다(개인 혹은 팀).
다음 모델을 중간에 저장해줄 ModelCheckpoint를 설정해주어야 하는데, monitor에는 우리가 checkpoint를 찍을 기준을 넣으면 된다. accuracy, val_loss등 개인이 설정하면 된다. 여기서 최적화를 어느 방향으로 할지를 mode에 넣어주는데, 우리 같은 경우에는 pearson이 최대가 되도록 최적화를 해주어야 함으로 max를 넣어주었다. save_top_k는 가장 성능이 좋은 체크포인트 중 몇 개를 저장할지이다. 우리 같은 경우에는 1개만 저장했다. 또한 weight만 넣는 것이 아닌 전체 모델을 넣어주는 save_weights_only에 False로 해주었다. 또 과대적합을 막기 위한 earlystopping이 필요한데, 여기서도 monitor는 같고 patience가 성능 개선이 없어도 몇 번 넘어갈 것인지를 설정해주는 것이다. 너무 높으면 early stopping이 제대로 동작하지 않을 가능성도 있다.
trainer = pl.Trainer(
gpus=-1,
max_epochs=cfg.train.max_epoch,
log_every_n_steps=cfg.train.logging_step,
logger=wandb_logger, # W&B integration
callbacks = [checkpoint_callback, earlystopping]
)이런식으로 logger=wandb_logger로 넣어주면 제대로 실행이 된다.
Wandb Sweep
Sweep은 하이퍼파라미터 튜닝을 위한 기능으로, 한 모델에 대하여 다양한 하이퍼파라미터 세트를 설정해주어 학습을 시킬 수 있다.
sweep_config = {
'method': 'bayes',
'parameters': {
'lr':{
'distribution': 'uniform', # parameter를 설정하는 기준을 선택합니다. uniform은 연속적으로 균등한 값들을 선택합니다.
'min':1e-5, # 최소값을 설정합니다.
'max':5e-5 # 최대값을 설정합니다.
},
'batch_size': {
'values': [16, 32]
},
},
'name' : 'snunlp-KcELECTRA-nof',
'metric':{'name':'val_pearson', 'goal':'maximize'},
'early_terminate' : {'type' : 'hyperband', 'max_iter' : 30, 's' : 2, 'eta': 3},
"entity" : 'sts',
'project' : 'ELECTRA'
}
checkpoint_callback = ModelCheckpoint(monitor='val_pearson',
save_top_k=1,
save_last=True,
save_weights_only=False,
verbose=False,
mode='max')
# Earlystopping
earlystopping = EarlyStopping(monitor='val_pearson', patience=2, mode='max')
# dataloader와 model을 생성합니다.
model_name_ch = re.sub('/','_',args.model_name)
def sweep_train(config=None):
wandb.init(config=config)
config = wandb.config
dataloader = Dataloader(args.model_name, config.batch_size, args.shuffle, args.train_path, args.dev_path,
args.test_path, args.predict_path)
model = Model(args.model_name, config.lr)
wandb_logger = WandbLogger(
log_model="all",
name=f'{model_name_ch}_{config.batch_size}_{config.lr}_{args.time_now}',
project=args.wandb_project,
entity=args.wandb_entity
)
trainer = pl.Trainer(gpus=1, max_epochs=10, log_every_n_steps=5,logger=wandb_logger,callbacks = [checkpoint_callback, earlystopping])
trainer.fit(model=model, datamodule=dataloader)
trainer.test(model=model, datamodule=dataloader)
output_dir_path = 'output'
if not os.path.exists(output_dir_path):
os.makedirs(output_dir_path)
output_path = os.path.join(output_dir_path, f'{model_name_ch}_{config.batch_size}_{config.lr}_{args.time_now}_model.pt')
torch.save(model, output_path)
sweep_id = wandb.sweep(
sweep=sweep_config, # config 딕셔너리를 추가합니다.
project=args.wandb_project,# project의 이름을 추가합니다.
)
wandb.agent(
sweep_id=sweep_id, # sweep의 정보를 입력하고
function=sweep_train, # train이라는 모델을 학습하는 코드를
count=7 # 총 5회 실행해봅니다.
)가장 먼저 sweep_config라는 딕셔너리가 보일 것이다. 이 것이 그냥 wandb와의 차이인데, sweep은 딕셔너리로 config을 작성한다. 다음 표를 보고 name, parameter 등이 의미하는 값을 이해하면 될 것 같다.
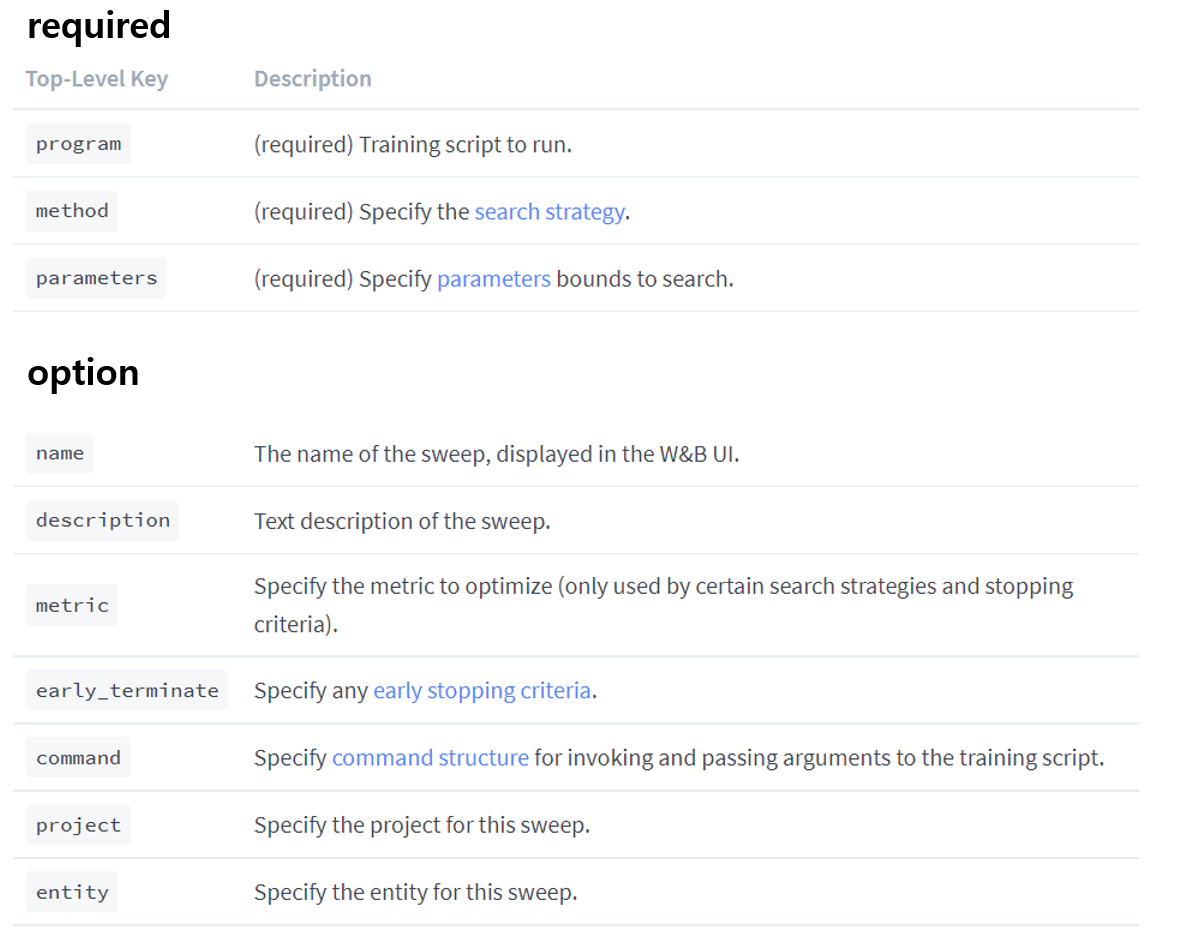
먼저 필수와 옵션이 있는데, method는 grid, random, bayes가 있다. grid는 우리가 정해준 세트 전부 다 학습을 하는 것이고, random은 균일분포로 하이퍼파라미터들을 가지고 와 학습을 하는 것이고, 베이스는 베이스의 조건부 확률에 기반하여 더 나은 하이퍼파라미터를 찾아주는 방법이다.
sweep_config을 만들었다면 이제 학습하는 코드를 짜줄 때이다. 우리가 위에서 학습하는 과정을 함수로 만들어야 하는데, 중요한 점은 sweep_config을 만들어줬다고 wandb_logger를 만들지 않으면 안된다는 점이다. 우리가 log를 찍을 metric, earlystopping, checkpoint 같은 부분은 그냥 wandb와 같게끔 sweep_train 안에 구현이 되어있어야 한다.(나는 wandb_logger를 안넣어줬다가 pearson metric을 남기지도 않고 earlystopping도 기능하지 않았다).
함수를 전부 만들어줬으면 이제 실행만 하면 된다. sweep_config과 프로젝트 이름을 넣어주는 sweep_id를 만들어 준 후, wandb.agent에 sweep_id, sweep_train을 function에 넣어주고, 마지막 count는 하이퍼파라미터 튜닝을 몇 번 진행할지 여부이다. 이 또한 config에 빼서 설정해주면 되겠다.
'DL' 카테고리의 다른 글
| 모델 학습 중 메모리 부족할 때 (0) | 2022.11.09 |
|---|
