
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Naver boostcourse
- 장고
- 백엔드
- 구현
- 프로그래밍
- AI Tech 4기
- sts
- 네이버
- 부스트캠프
- QNA 봇
- Customer service 구현
- 프로그래머스
- Django
- AI Tech
- 4기
- 웹 프로그래밍
- cs50
- 레벨2
- 파이썬
- Naver boostcamp
- 풀스택
- 웹
- 서블릿
- boostcourse
- P Stage
- BOJ
- 백준
- 대회
- 서버
- 2021 Dev-matching 웹 백엔드 개발자
- Today
- Total
daniel7481의 개발일지
모델 학습 중 메모리 부족할 때 본문
협소한 견문이지만 P Stage를 진행하면서 OOM이 발생할 때마다 slack에서 다른 분이 올려주신 부분을 보다 보니 직접 정리해야하겠다는 생각이 들었다. 그래서 두 가지 용량 문제를 해결했던 방법을 적으려고 한다.
CUDA out of memory
확실하지는 않지만! CUDA에서 메모리가 부족하다는 것은 RAM에서 자원이 부족하다는 뜻 같았다. 나 같은 경우에는 다른 모델 학습을 하고 있는데 또 다른 모델 학습을 하려고 한다거나(모델을 많이 돌리다보면 전에 돌리던 모델이 끝난 줄 알았는데 몰래 학습하고 있었던 경우가 많았다) 이런 경우에 자주 발생하는 것 같았다. 이럴 때 해결 방법은
1. 만약 전에 돌리고 있던 학습이 끝나야 하고 현재 모델을 돌려야 할때
ps -ef로 지금 진행 중인 process를 볼 수 있다.
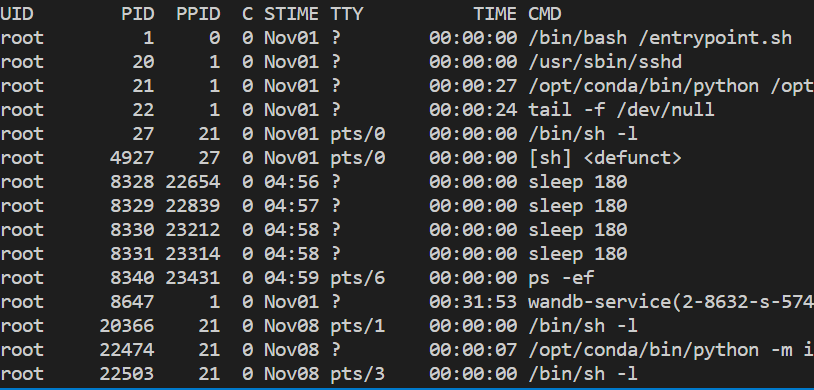
자신이 실행했던 script에 해당하는 PPID를 복사한 다음 kill -9 {PID}로 해당 process를 끝낼 수 있다. 그런 다음 모델 학습을 하면 문제가 없다. 위 과정을 진행하면 대부분 문제가 해결되었는데, 만약 해결되지 않았다면 torch.cuda.empty_cache() 터미널에서 한 번 실행해주거나 배치 사이즈를 낮춘 다음 GPU cleaning(노트북이라면 커널 재시작)을 한 번 해준 후 다시 실행해주면 되겠다. 혹은 pip install GPUtil >> import GPUtil >> GPUtil.showUtilization( )로 현재 GPU 사용량을 보고 어떤 부분에서 메모리가 많이 잡아먹는지 해결하고, inference시에 with torch.no_grad() 등을 잘 해줬는지 확인하면 된다
물리적 스토리지 캐시가 부족할 경우
모델을 많이 돌리다보면 모델의 output과 logging 파일이 쌓여서 물리적인 스토리지가 부족할 수도 있다. OSError: [Errno 28] No space left on device 라는 에러 메세지가 이를 의미한다. 이런 경우에는 직접 스토리지에서 용량을 많이 차지하는 것이 무엇인지 확인해야 한다. 먼저 df -h로 물리적 스토리지 용량을 확인한다.
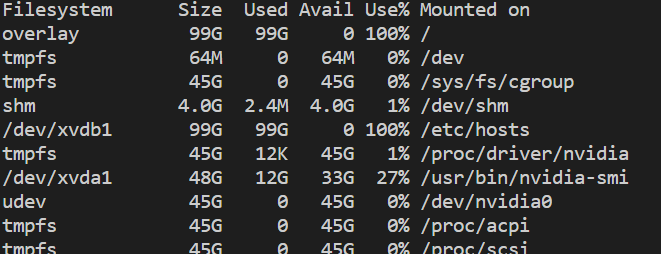
99G가 사용된 것을 알 수 있다. 이제 직접 비워줘야 한다.
이제 각 디렉토리를 돌아다니면서 du -d 1 -h /로 용량을 파악할 수 있다.
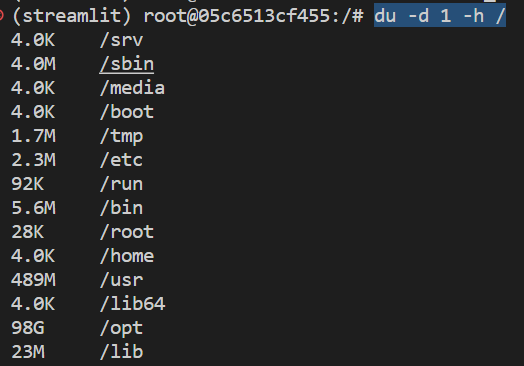
만약 용량이 많이 나가는 디렉토리가 있고, 별로 중요하지 않은(현재 학습에 필요하지 않은)내용일 경우 rm -rf {디렉토리 이름}으로 지워줄 수 있다. 나 같은 경우에는 학습 후 .cache 디렉토리에 많은 불필요한 용량이 쌓였고, rm -rf ./.cache로 지워주면 3~40G는 확보할 수 있었다.
이 외로도 아주 많은 문제와 메모리 문제를 맞이할 것 같다. 지금은 aistages에서 제공해준 훌륭한 서버로 별도의 문제는 발생하지 않았지만, 기본적인 것부터 작성해보려고 한다.
'DL' 카테고리의 다른 글
| Wandb와 Sweep 구현 (0) | 2022.11.03 |
|---|
