
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 백준
- 구현
- cs50
- 백엔드
- 웹 프로그래밍
- 파이썬
- P Stage
- Django
- BOJ
- 네이버
- 부스트캠프
- 레벨2
- 장고
- 2021 Dev-matching 웹 백엔드 개발자
- AI Tech 4기
- boostcourse
- 프로그래머스
- 웹
- 4기
- Customer service 구현
- 서버
- 풀스택
- Naver boostcourse
- sts
- Naver boostcamp
- QNA 봇
- 대회
- 프로그래밍
- AI Tech
- 서블릿
- Today
- Total
daniel7481의 개발일지
P Stage: Relation Extraction 본문
문제 정의
문장 안에서 Entity(단어)가 2개 주어졌을 때, 문장 내에 두 단어의 관계를 예측하는 task다.
ex)

이번 대회에서 EDA를 맡게 되었고, 가장 먼저 데이터를 하나하나씩 뜯어보면서 우리가 풀어야할 문제를 정의하려고 하였고, 데이터 시각화를 통해 여러 가지 인사이트를 발굴했다.
EDA
데이터셋은 KLUE Datset을 사용했으며, 칼럼은 id, Sentence, subject_entity, object_entity, label, source로 나뉜다.
id: 인덱스다
Sentence: Entity가 포함된 문장들이다.
subject_entity: Entity 간의 관계를 파악할 때 주어가 되는 단어다. 예로 들어 label이per:children이라면 subject_entity의 type은 person이다.
object_entity: Entity 간의 관계를 파악할 때 목적어가 되는 단어다. 위 예시에서 children이 object_entity의 type이다.
label: 30개의 class 라벨이다. 30개의 라벨은 no_relation, per:, org: 세 가지 경우로 나뉜다.
source: 이 데이터셋을 가져온 출처다. Wikipedia, Wikitree, policy_briefing 세 가지 종류가 있다.
칼럼 별로 데이터 분석을 진행하였다.
Sentence column
Sentence 길이 시각화
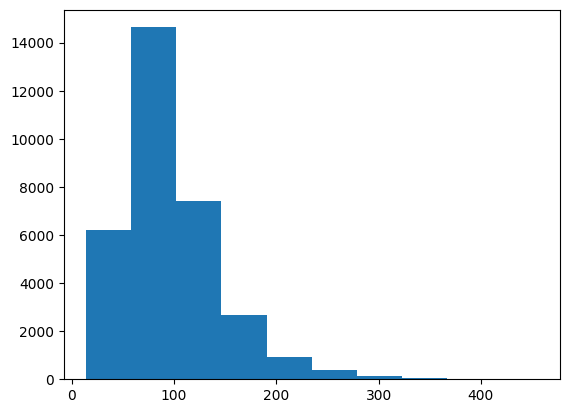
위 그래프의 x축은 문장의 길이, y축은 갯수다. 시각화 결과 train_data, test_data 모두 동일한 분포를 가지고 있었다. 문장의 길이는 대체로 긴 편이었으며, 이를 통해 Entity의 위치가 embedding size인 512를 넘어가는 데이터가 존재할 것이라는 생각을 하게 되었다.
한자가 포함되어 있는 데이터
확인 결과, Sentence에 한자가 포함되어 있는 데이터는 2504개였다. Subject/object entity에서도 한자가 포함되어 있는 데이터도 확인되었다. 추후 hanja 라이브러리를 사용하여 한자를 한국어로 변환하는 실험을 진행했다.
Subject / Object Entity
먼저 subject / object entity의 형태를 살펴보았다.

딕셔너리 형식으로 작성되었음에도 String 형식으로 저장되었다.
베이스라인 코드의 전처리 함수에서 오류를 발견하였다.

baseline result
{'word': '희극 배우, MC, 배우, 가수', 'start_idx': 32, 'end_idx': 48, 'type': 'POH'}
entity ‘word’: 희극 배우
Fixed:
entity ‘word’: 희극 배우, MC, 배우, 가수
Entity의 word 안에 쉼표가 존재하는 데이터셋은 전부가 들어가는 것이 아니라 맨 앞 단어만 들어가게끔 되어 있었다. Entity word안에 쉼표가 존재하는 데이터는 약 70개 정도 밖에 없었지만, 이 쉼표로 나누어진 데이터를 통해 추후 증강을 진행하였다.
Entity가 embedding size를 넘어가는 데이터 확인
Tokenizer의 return_offsets_mapping 인자를 True로 설정하여 tokenizing 후에도 entity의 위치를 확인하였다. 이를 통해 Entity의 위치가 512를 넘어가는 데이터는 학습에 혼란을 줄 것으로 파악되어 약 70개 정도의 데이터를 drop 해주었다.
Label Column
30개의 클라스의 빈도 수를 시각화 해주었다.

확연한 클라스 간의 불균형이 확인되었고, 추후 Focal loss를 활용하는 등 라벨 불균형을 해결하려고 노력하였다.
Source Column
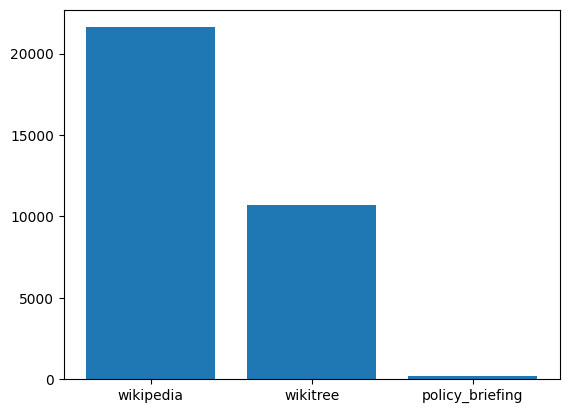
시각화 결과 wikipedia, wikitree, policy_briefing 세 가지 종류가 있는 것이 확인되었고, 세 가지 출처 특성상 문어체로 작성 되어 있는 것으로 예측했고, 추후 backbone 모델을 선택할 때에 pretrain datset가 문어체로 이루어진 모델들에 집중하였다.
Experiments
실험 결과
| Condition | eval_loss | eval_micro_f1_score | eval_auprc | eval_accuracy | # of Data | inference(micro f1) | inference(auprc) |
| Base | 0.8814908266067505 | 81.51658767772513 | 74.18295304741712 | 0.7947336002463813 | 25976 | 62.1118 | 63.5269 |
| Base(preprocessing fixed) | 0.8115533590316772 | 83.71089536138079 | 77.29641123006817 | 0.8176778564829073 | 25976 | 62.6380 | 61.6267 |
| Aug_one | 0.8311185836791992 | 83.41437061048082 | 77.76530982213737 | 0.8144441022482292 | 26097 | 62.0132 | 60.9910 |
| Aug_combination | 0.8233703970909119 | 83.82195591696984 | 77.91302218583246 | 0.8216815522020327 | 33049 | 63.9556 | 63.8575 |
| Aug_permutation | 0.778175413608551 | 83.23128155548395 | 75.7950872568299 | 0.8127502309824454 | 95827 | 50.4120 | 46.6036 |
| hanja_to_kor | 0.8147274255752563 | 81.57000328911302 | 74.10645410553387 | 0.7945796119494919 | 25976 | 60.0056 | 64.7050 |
| hanja_to_kor_com | 1.071782112121582 | 82.21212457054195 | 73.52723325660006 | 0.8058207576224207 | 25976 | 62.3361 | 61.1169 |
| oversized_del | 0.6476 | 83.04728158564943 | 74.884 | 0.8107 | 25205 | 62.4557 | 63.9982 |
Augmentation
위와 같이 word가 쉼표로 구분지을 수 있는 데이터의 개수는 train_data 안에 45개가 있다. 쉼표로 구분지은 entity들은 동일한 entity type을 가질 것이라고 가정하였고, entity를 제외한 나머지 칼럼(sentence, label, source)는 유지하고 entity만 나눠줘서 데이터를 증강해 주었다.
쉼표로 나눈 데이터들, 위 경우에는 [희극배우, MC, 배우, 가수]인데, 이 배열을 하나씩 나눠서 증강해주는 방식이 (aug_one)이며, 이 배열의 조합을 증강해준 것이 aug_com이고, 이 배열의 순열을 증강해준 것이 aug_per이다.
결과적으로 배열의 조합을 증강해준 aug_com이 가장 좋은 성능을 보였고, baseline 대비 micro f1에 대하여 1.3이상의 성능 개선을 보였다. aug_one, aug_com은 뚜렷한 성능 개선이 없었다. 이 결과에 대한 이유로 다음과 같은 추측을 할 수 있었다.
- Aug_one은 121개의 데이터만 추가되었고, 전체 데이터셋의 크기 대비 미미한 양의 증강이라 효과가 없었던 것으로 추정된다.
- Aug_com 같은 경우 7073개의 데이터가 증강되었고, klue dataset 내부에서도 sentence가 중복되는 데이터 수가 3000개가 넘기 때문에, 전체 데이터에 편향성을 줄 정도의 증강이 아니었던 것으로 추정된다. 증강된 데이터의 entity도 모두 다른 조합이므로, 모델의 표현력을 높이는 효과를 준 것으로 추정된다.
- Aug_per 같은 경우 약 7만개 이상의 데이터가 증강되었다. 원래 데이터의 크기가 25976개였던 것을 감안하면, 데이터의 편향을 아예 바꿀 정도의 양이다. 증강된 데이터에만 모델이 집중하도록 유도가 되어서 실제 inference에서는 좋은 성과를 내지 못했던 것 같다.
Hanja_to_kor
Train data의 sentence column 에 한자가 포함되어 있는 데이터의 개수는 2504개이고, subject entity에 포함되어 있는 데이터의 개수는 3개, object_entity는 175개였다. 또한 test_data에서는 각각 406, 33, 24개였다.
Klue/bert-base tokenizer를 통해 확인한 결과 vocab에 들어있지 않는 한자들은 <unk> 토큰으로 대체되는 것을 확인하였다.
"{'word': '金基昶', 'start_idx': 4, 'end_idx': 6, 'type': 'PER'}” ['金', '基', '[UNK]']
이를 해결하기 위해 hanja 라이브러리를 사용하였고, 두 가지 옵션이 존재했다.
- substitution: 한자를 한국어로 대체하는 옵션
- 'combination-text': 한자의 한국어를 bracket 사이에 넣어주는 옵션(ex: 金基昶(금기창))
두 옵션 모두 큰 효과를 보지 못하였다. 이 결과에 대해 다음과 같은 추측을 할 수 있었다.
- 데이터셋 내부 대부분의 한자는 사람의 이름이다.(wikipedia, wikitree 특성상) 대부분의 한자 경우 이름(한자) 식으로 되어있으므로, 한자의 한국어 음이 대부분의 경우 주어졌으므로, 한국어로 변환해도 큰 효과를 보지 못했던 것으로 추정된다.
- hanja 라이브러리로 한자를 한국어로 번역 시 두 가지 이상의 음을 가지는 한자에 취약하다. 위 예시를 들면 金基昶은 실제로 김기창이지만, 번역시 금기창이 된다. 이는 정보의 왜곡으로 이어질 수 있으므로, 오히려 성능이 떨어지는 결과로 이어진 것 같다.
Oversized_del
우리 팀의 경우 tokenizer의 embedding size를 학습 효율을 위하여 최대 512로 보았다. 하지만 klue dataset의 sentence 칼럼의 값들은 대체적으로 길이가 길었다.(아래 그래프의 x축은 문장의 길이, y축은 갯수다)
단순히 문장의 길이만으로 512를 넘어가지 않는다고 확신할 수 없었고, 실제로 tokenizing을 한 값을 토대로 subject / object entity의 위치가 512를 넘어가는 경우를 drop해주었다.
An Improved Baseline for Sentence-level Relation Extraction

| Method | eval_f1 | eval_auprc | inference_f1 | inference_auprc |
| bert-base | 83.71089536138079 | 83.71089536138079 | 62.6380 | 61.6267 |
| Entity mask | 83.26461570990591 | 76.52407859243088 | 40.2905 | 38.7714 |
| Entity marker | 82.55309926311227 | 75.95485253894314 | 54.9873 | 53.3891 |
| Entity marker(punct) | 82.97755883962779 | 75.15339575561447 | 57.8795 | 58.1863 |
| Typed entity marker | 82.86281429201587 | 73.9305362530267 | 56.4742 | 55.0037 |
| Typed entity marker(punct) | 80.77239112571898 | 67.82235926263863 | 58.1295 | 51.2219 |
5가지 실험 모두 baseline 대비 성능 개선을 이뤄내지 못했다. eval 단계에서는 높은 성능을 보였으나 실제 inference에서 좋은 성과를 내지 못한 것으로 보아, 구현 단계에서 문제가 있었던 것으로 파악된다.
Dataset 제작 실습을 진행하면서 위의 영어인 PERSON, ORGANIZATION 등을 한국어로 변환해서 <S:사람>, @ * 사람 * @ 형식으로 다시 구현할 예정이다.
결론
EDA를 처음 담당하면서 데이터를 직접 하나하나 찍어보면서 이해하니 프로젝트를 이해하기 훨씬 쉽다는 생각이 들었다. 또한 데이터를 제대로 이해해야 이후에 사용할 방법론을 선택하는데에 있어서 많은 도움이 되었던 것 같다. 이번 데이터셋과 task는 너무나 유명해서 정형화된 틀이 이미 존재한다는 것을 확인했고, 남들과 같은 차별화된 결과를 만들고 싶다는 생각에 데이터에 매진되어 어떤 결과든 만들려고 했던 것 같다. 프로젝트를 이해하는데에는 많은 도움이 되었지만, 추후에는 논문이나 다른 사람들이 시도해서 효과를 본 방법론을 활용해보고 싶다.
'AI Tech 4기 > Level2' 카테고리의 다른 글
| P Stage: MRC (0) | 2023.01.09 |
|---|---|
| P Stage: 데이터 제작 (0) | 2022.12.22 |

