
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 레벨2
- 풀스택
- Customer service 구현
- 2021 Dev-matching 웹 백엔드 개발자
- sts
- 파이썬
- 서버
- Naver boostcamp
- 부스트캠프
- Naver boostcourse
- QNA 봇
- AI Tech 4기
- Django
- 4기
- 웹
- 웹 프로그래밍
- boostcourse
- 프로그래머스
- 장고
- P Stage
- AI Tech
- 대회
- 백준
- 백엔드
- 서블릿
- 구현
- 프로그래밍
- 네이버
- cs50
- BOJ
- Today
- Total
daniel7481의 개발일지
P Stage: MRC 본문
Pytorch Lightning Refactoring
Baseline / PL 코드 도식화
Baseline 도식화

베이스라인 코드를 이해하기 위해 가장 먼저 도식화를 진행하였다. 도식화를 통해 각 코드에서 모듈이 어떻게 이어져 있는지, 각 모듈의 기능 등을 시각적으로 나타내기 위해 그림으로 이어주었다. 또한 이를 토대로 어떤 모듈을 pytorch lightning 코드에 재활용 할 수 있을지를 생각하고, Pytorch lightning 코드 또한 구현에 앞서 도식화를 하였다.
Pytorch lightning 도식화

도식화를 진행하기 전에는 머릿속이 뒤죽박죽이었지만, 베이스라인 코드를 도식화한 후 pytorch lightning 또한 미리 설계하듯 도식화를 하자 재구현이 훨씬 쉬워졌다.
pl
├─ UPDATE.md
├─ config
│ └─ base_config.yaml
├─ datamodule
│ └─ base_data.py
├─ inference.py
├─ main.py
├─ models
│ └─ base_model.py
├─ output
├─ retrievals
│ ├─ BM25.py
│ ├─ base_retrieval.py
│ ├─ elastic_retrieval.py
│ ├─ elastic_setting.py
│ └─ setting.json
├─ sweep.py
├─ train.sh
├─ tune
│ ├─ batch_find.ipynb
│ └─ lr_find.ipynb
├─ utils
│ ├─ data_utils.py
│ └─ util.py
└─ wandb
베이스라인 코드를 재구현하는 가장 큰 이유는 모듈화였다. 빠른 실험을 위해서는 베이스라인 코드를 사용하는 것이 좋겠지만, 향후 다양한 실험을 하거나 새로운 기능을 추가할 시에 코드의 가독성이 떨어질 것이라 판단하였고, 이는 시간 낭비로 이어질 수 있겠다 생각이 들었다. 그래서 디렉터리를 데이터 모듈(dataset, dataloader), config(train.sh에 들어갈 config 파일), models(Custom model), retrievals, utils(데이터 전처리, 후처리 모듈, metric 모듈)로 나누어서 구현하였다.
Curriculum learning
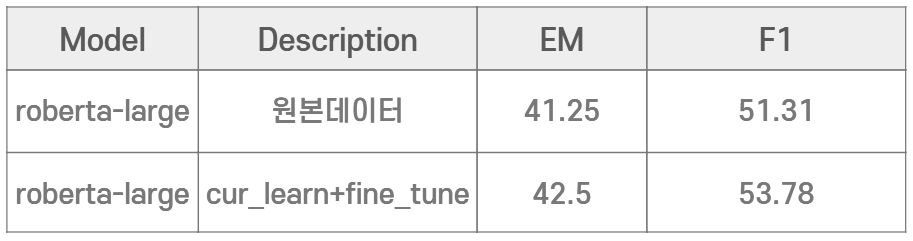
Daniel Campos의 Curriculum Learning For Language Modeling 논문의 Context의 길이가 길수록 더 많은 의존 구문 추적을 요구하기에 난이도가 올라간다( It is a lot harder to model longer sentences, as longer sentences require better tracking of dependencies) 아이디어를 차용하여, 모든 데이터셋을 context 길이 순으로 정려 한 후, shuffle=False로 설정하여 sequential하게 학습되도록 설정하였다. 동일한 환경에서 학습한 결과 inference em이 1.25 정도 상승하는 결과를 보였다.
외부 데이터 TAPT
외부 데이터셋이 허용된다는 룰을 확인 한 후, Klue MRC와 유사한 korquad, wiki(AI hub) 데이터셋을 사용하기로 결정하였다. Korquad와 wiki 데이터를 합치면 대회 데이터의 30배 정도의 데어티였고, 대회 데이터와 합쳐서 학습한 결과 오히려 성능이 하락했고, 외부 데이터를 먼저 학습 했을 때 epoch를 1보다 크게 줄 경우 외부 데이터에 과적합 되어서인지 성능이 떨어졌다. 이를 통해 규모가 큰 데이터에 과적합되지 않되, TAPT로 표현력을 높이기 위해 1 에포크로 학습한 후 대회 데이터로 재학습한 결과 baseline 대비 em이 5 이상 상승하는 효과를 낼 수 있었다

BM25
Baseline 코드는 retrieval model이 tf-idf로 되어 있었고, sparse retrieval에 있어서 SOTA로 평가 받는 BM25를 활용하기 위해 BM25.py를 구현하였다.
발표
운이 좋게도 private 2등을 거두게 되어, 발표를 하게 되었다. 실험적인 부분은 대부분의 팀들이 실행했을 거라고 생각하였고, pytorch lightning, 우리 팀의 협업 / 소통 방법을 중점으로 설명하려고 하였다. 많은 사람들 앞에서 발표하는 것은 생각보다 떨렸지만 좋은 경험이었던 것 같다.
'AI Tech 4기 > Level2' 카테고리의 다른 글
| P Stage: 데이터 제작 (0) | 2022.12.22 |
|---|---|
| P Stage: Relation Extraction (0) | 2022.12.05 |

